
Capture Platform Capabilities
Client Challenge
Hundreds of thousands of documents of all types – paper, emails, file attachments, faxes, etc. – may reach an enterprise business every day, especially when customers are mainly private consumers or end users. Typically, this incoming information is a mixture of known forms, semi-structured accounting documents and totally unstructured letters from customers, all appearing with either printed or handwritten text information.
A primary challenge of running satisfactory operations is processing these documents, as they are received, in a standardized and efficient way that will quickly start activities triggered by the content of these documents. Goals for efficiency may include short STP rates for incoming documents, handling daily or monthly peaks without excess additional personnel, and easy distribution of various data completion work throughout an organization.
Solution Description
The rich Capture Framework Solution from Papyrus Software provides all the necessary out-of-the-box Capture Standard processes. Based on the powerful Papyrus Objects Metasystem Architecture and Papyrus WebRepository infrastructure, the solution includes built-in database (Depot), Papyrus EYE GUI for Manual Verification of Recognized Data via desktop or Web Portal, interface with all types of documents and data with more than 20 available adapters. Further, innovative mechanisms like patented “User Trained Agent” (UTA) allow user-guided setup of approved Capture workflows.
Papyrus Multi-Channel Capture Platform
Studies have found that up to 75% of all documents received and manually keyed into a data collection system contain some type of error. However, the Papyrus Capture platform solution automates document processing with speed of accuracy regardless of the input method. Papyrus Capture can meet all of your corporate inbound document requirements without the need for complex programming.
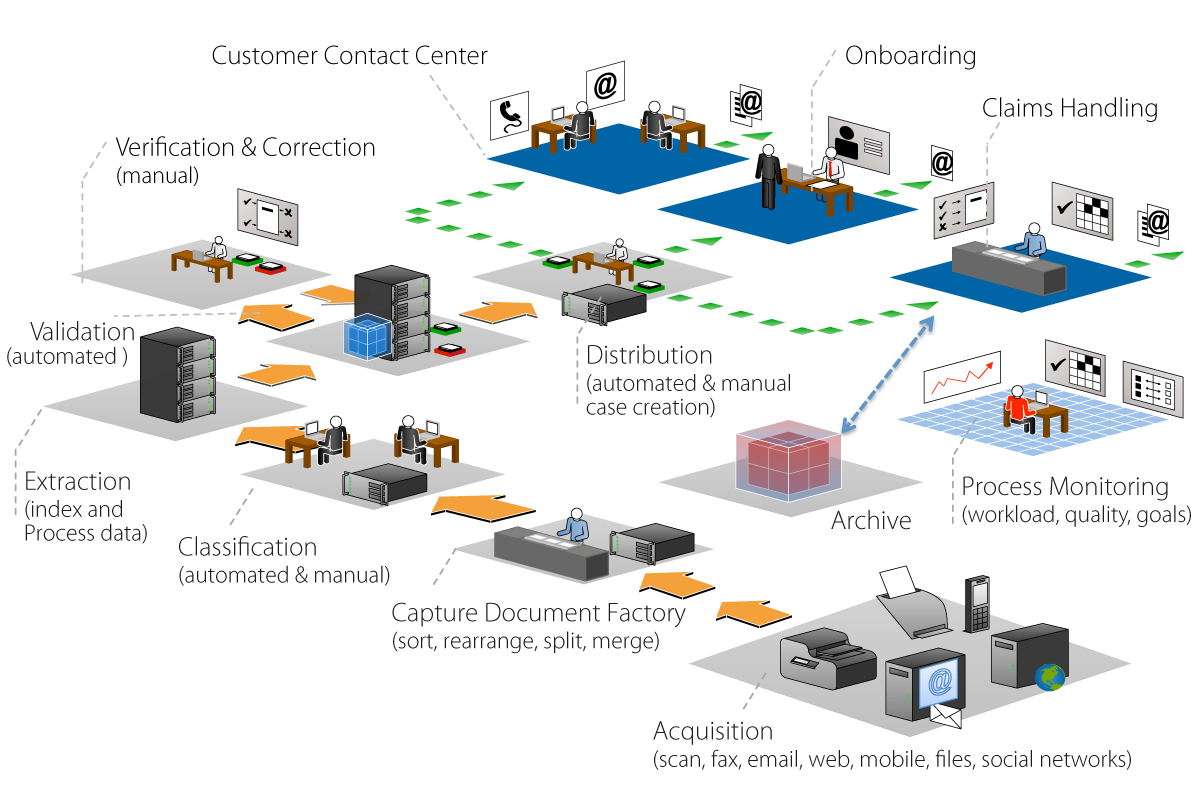
Papyrus Capture and Adaptive Case Management
Automate and Digitize Inbound Mail Channels
Incoming mail/scanning Documents are often received as paper documents that Papyrus Capture then transforms into business-critical information by scanning, digitally signing and encrypting the data.
Incoming faxes Papyrus provides the ISDN interface for all common fax machines. Fax documents received are indexed directly at the source and then shared throughout the organization based upon roles and privileges.
Incoming emails For emails, neural network functionality is used to compare similarities and differences between incoming emails and those stored in the domain knowledge base that's build up by examples. Words and phrases in the body text are also used to classify an email, not just those in the subject line.
Web response Papyrus software allows for a Web application for customers to fill out HTML or PDF response forms. These are captured with the Papyrus HTTPs Adapter and processed accordingly.
SOAP application message A SOAP message can be used to communicate information from a 3rd-party application server, Java application, Web portal or any other Web services-enabled system.
Social The Papyrus Social Adapter integrates with Facebook, Twitter and LinkedIn.
Mobile Capture Integration Papyrus Capture/Mobile enables flexible, accurate data entry and real-time processing from customer, remote staff or field service devices – for a seamless and interactive omni-channel customer experience.
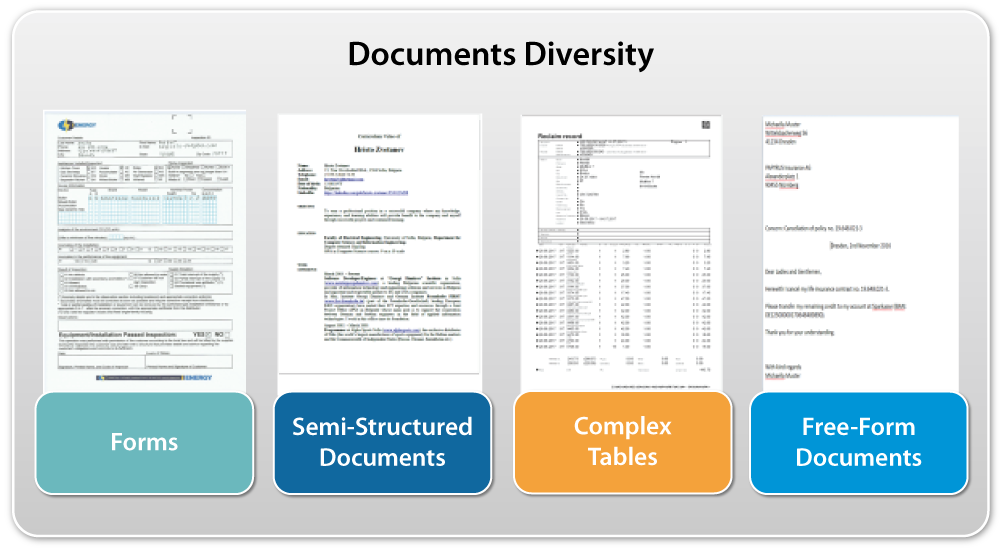
Documents Diversity
Papyrus Capture Platform Architecture

Inbound Mail Capture
Acquisition module - provides several options for
document import (integrated scanning of documents, import of
image files in various formats) in batches, email through the
POP3 Adapter or MAPI adapter but also Twitter messages.
Capture Document Factory module - sorts, rearranges,
splits the imported document pages according to
requirements.
Classification module - assigns the document class
(taxonomy) to the document using different classification
algorithms.
Extract module - extracts the information (structured
data) using patterns and AI of the document.
Document Validation - manual and automatic validation
of extracted data with support for lookup in external database
or REST
Distribute - distribution of document and extracted
data for further business processing, export to third-party
applications, export to file system or an external database,
or archiving.
Authorization, Security and Auditing
The User-Role-Privilege Concept is the basis for granting each user in the system the specific rights to view, change and enter the data he/she is authorized for. The Papyrus EYE UI masks for Document handling and Data Verification are highly customizable to follow your CI standards and business requirements.
- Access rights by user and role
- LDAP Adapter
- Audit trail
- Document SSL encryption (AFP and PDF)
- Digital signature (PKI Public Key Infrastructure)
- Secure HTTPS Adapter
User-Trained Inbound E-Mail and Document Capture
Training machines to recognize documents and messages while continuously optimizing data capture is a remarkable technology to increase efficiency. The Business Designer for Capture supports non-technical users to ad-hoc train state-of-the-art classification processes for machine learning, utilizing pattern recognition to increase accuracy and efficiency of data capture in fixed-form and free-form emails, scans, fax, PDFs, office documents and handwritten information.
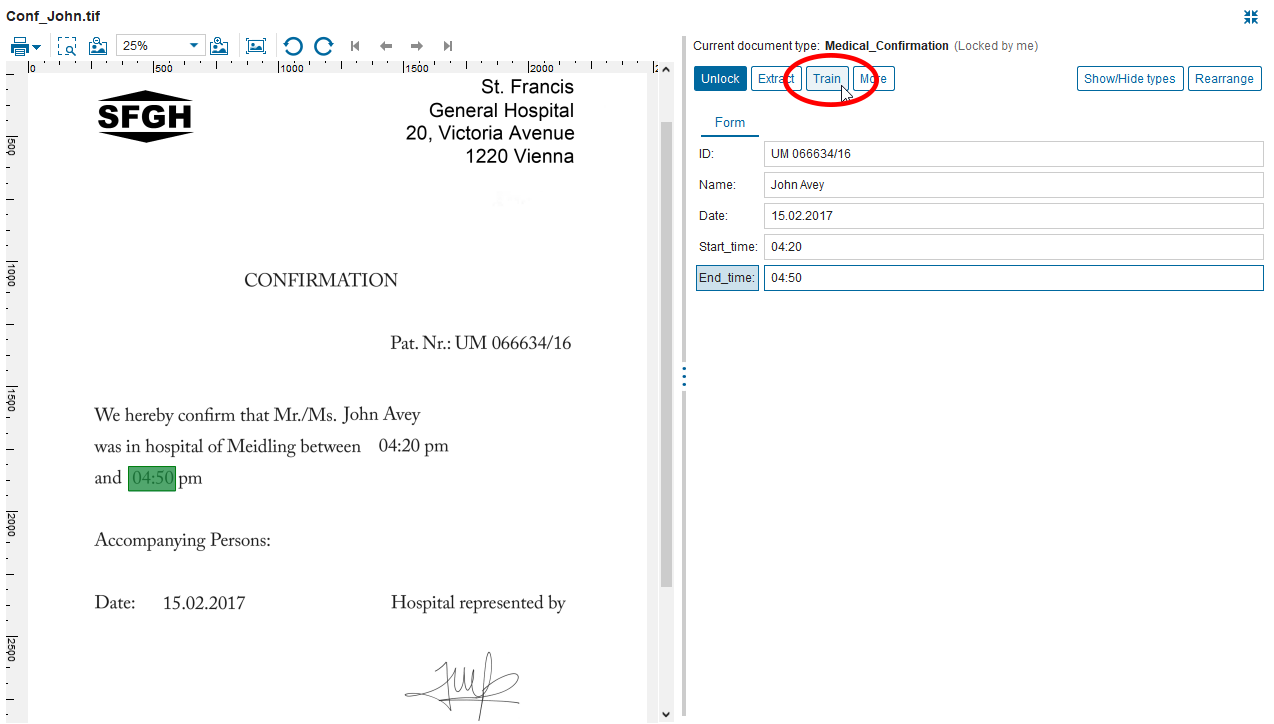
Papyrus Business Designer - Capture
User-trained Classification Process
The Papyrus Capture Classification methodology is independent of document type because the categorizer is typically trained through the use of examples. From this input the classification process learns specific similarities and distinctive differences. User-trained technology ensures that all types of documents can be classified based on properties such as, keywords, layout, logo, text, barcode and statistical data. For documents that cannot be classified correctly, constant fine-tuning is possible with Papyrus Designer/Capture. This technology ensures continuous optimization and enables flexible adjustment of classification rules if new document variants become part of the processing.
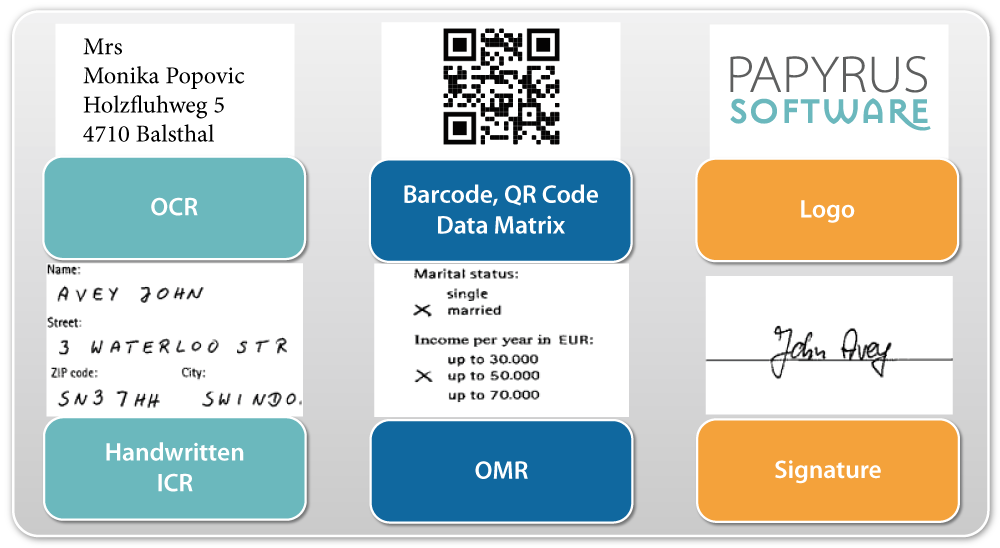
Classification Properties
Intelligent Extraction Process
Based on advanced OCR/ICR – a combination of Papyrus' own development and a market leader engine – printed and hand written documents can be analyzed and data fields of interest automatically extracted regardless of whether or not the position on the page is known. Immediate fuzzy logic-based matching uses calculations to assess the probability of the contents of a predefined data field for dramatically improved results.
Papyrus Fixform uses four OCR/ICR engines with advanced image preprocessing for improved document recognition. It provides indexing and processing of data extracted from known forms on predefined document positions, Manifold parametrization and post-processing text filter functions enable best possible up to 100% recognition automation.
Papyrus Freeform automatically recognizes scanned but unsorted business documents of unknown structure and layout. The system also analyzes unstructured or poorly structured document with great reliability and is capable of processing an kind of business document, such as emails, PDFs, correspondence , invoices copied forms, job applications and more.
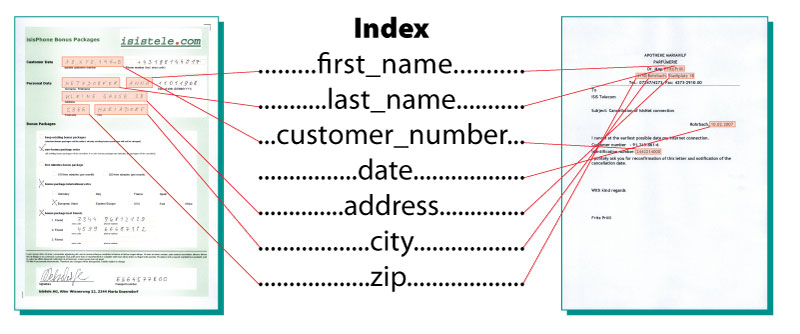
Index extraction
Papyrus Capture/Mobile
With accurate data entry and real-time processing from customer, remote staff or field-service devices, Papyrus Capture/Mobile offers a seamless, interactive omni-channel customer experience.
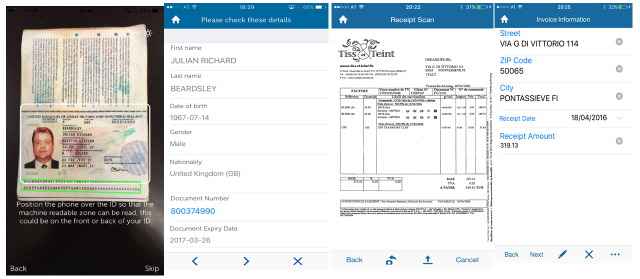
Papyrus Mobile Capture Product of the Year
Papyrus intelligent Inbound Mail Capture Solution Platform provides a self-learning, user-trained document/data automated capture across channels via one single definition. It ingests all kinds of structured and unstructured communication, including handwriting and routes extracted data directly to individual/department inboxes, enterprise applications and customer cases and triggers processes based on rules, cutting processing times from days to hours. The self-learning classification process and machine learning increase efficiency and limit human interaction to QA or exception handling.
Value Delivered
Key Features
-
Automated classification of incoming documents across
channels
- Paper, email, Web, FTP, Social and fax
- User-trained system optimizes automatic classification to nearly 100% for incoming invoices
- Business Designer for user-trained capture – training the machine
-
Automated reading of emails, letters, invoices, PDFs, forms
with OCR/ICR
- Recognition for barcodes, plus printed and handwritten documents
- Multilingual documents and GUI support
- Manual correction workplace
-
Three methods of page classification
- Document Sorter to combine all elements belonging to one document
-
High-Capacity data extraction tools
- Geometrically structured documents (“Server/FixForm”)
- Unstructured documents (“Server/FreeForm”)
-
Rules and processes defined in the Papyrus Desktop
- Executed by the system, including highly important dataset validations
- Workflow definition and execution for exceptions, corrections and approvals
-
Integrated security
- Authentication, authorization, auditing, encryption, HTTPS
- Digital signature PKI support
-
Business application, legacy system and storage integration
- Wide range of Adapters and Typemanager interfaces
- Comprehensive document and object support – MS Office, SMS, chat session, wiki pages, HTML, XML, PDF, audio, video, CAD/CAM, X-ray, photos, etc.
- Seamless integration to Papyrus WebArchive or any other third-party vendor archive
- Node-based architecture
Key Benefits/Value
- Enterprise-level software solution for consolidation, integration and automation of capture activities
- Capture capability fully integrated with freely definable process flow
-
All inbound channels are supported
- Paper, email or fax
- Invoices and bills, delivery notes, work confirmations, orders, credit notes
- Improved accuracy and customer response through automated, rules-based recognition
- Compliance for required data verifications and response guidance
- Fast implementation of processes and changes = lower cost of ownership
- ROI potential within 12-18 months
-
Highly automated process offers process agility and
flexibility
- Same process independent of input channel type
- Applicable for central and decentralized organizations
- High level of personalization based on document or content types
- No database administrator required
- Platform and input channel independence
- Multi-platform scalability
Product Configuration: Business Document Capture
-
Papyrus Designer/Capture
Graphical definition for extracting text keywords and data fields from scanned images, e-mails, SOAP messages or faxes -
Papyrus Business Designer
A user friendly WYSIWYG design tool for easy definitions when digitizing business content with a user-trained capture capability. -
Papyrus Recognition Server
Automated "machine-learning-technology," pattern recognition, contains OCR/ICR (5 engines) and "Context Fuzzy Record Associator," image correction, document classification, data extraction and validation, email text classification, distributed archiving and automated content replication. -
Papyrus Client/Capture
Manual correction on the desktop or in the browser. -
Papyrus WebRepository
Central point of administration and maintenance, including versioning, validation, change management, user authorization, business rule definition and process management definition. Administration of document content with record management and security functionality. -
Papyrus Scan Client
Scanning of incoming mail -
Papyrus Adapter/POP3 – MAPI, IMAP
E-mail receiving and handling. -
Papyrus Adapter/Fax
Receiving and handling of incoming faxes. -
Papyrus Adapter/REST
Webservice integration
Optional Components: Capture Integration
-
Papyrus WebArchive
Stores and offers instant retrieval of indexed electronic incoming and outgoing documents, e-mails, data, voice, video and other content in many formats. Direct viewing in AFP, PDF and TIFF. Interface to third-party archives using standard adapters (XML and CMIS). -
Papyrus Adapter/LDAP
Interfacing directly via defined user roles -
Papyrus Adapter/MQ Series or SOAP Adapter
Definable messaging interface for business data. Compiler- and platform-independent. -
Papyrus Adapter/SAP XOM
Connecting and integrating business document capture solution with existing ERP system(s).