
Capture your business data with Papyrus Business Designer
Our long experience with Papyrus Capture for inbound mail data extraction took a big step forward by integrating it into the Papyrus Business Designer. It provides with unprecedented simplicity the full power of data recognition to your business departments – no IT involvement anymore. Business administrators can extract data from structured and unstructured documents, whether these are available as images from scans, or in any other document format.
Data extraction via drag-and-drop
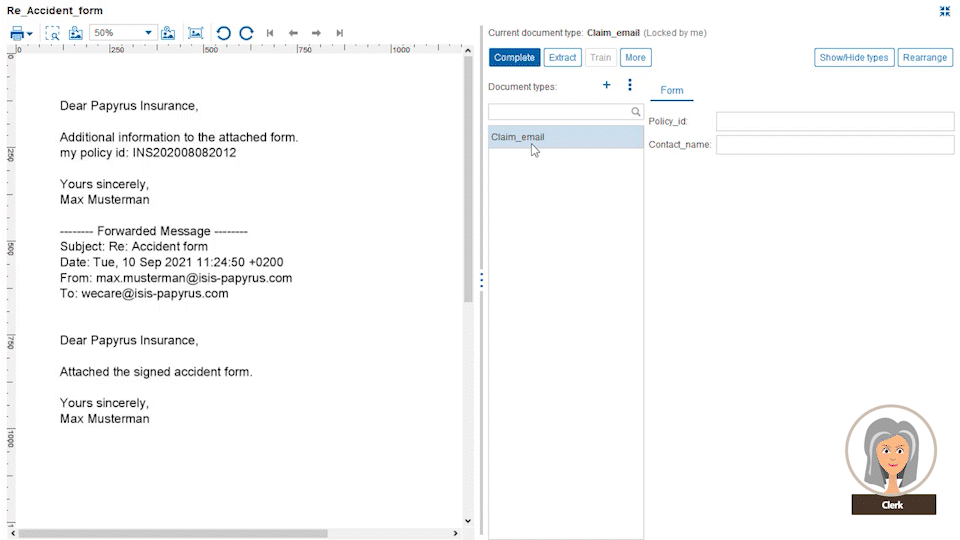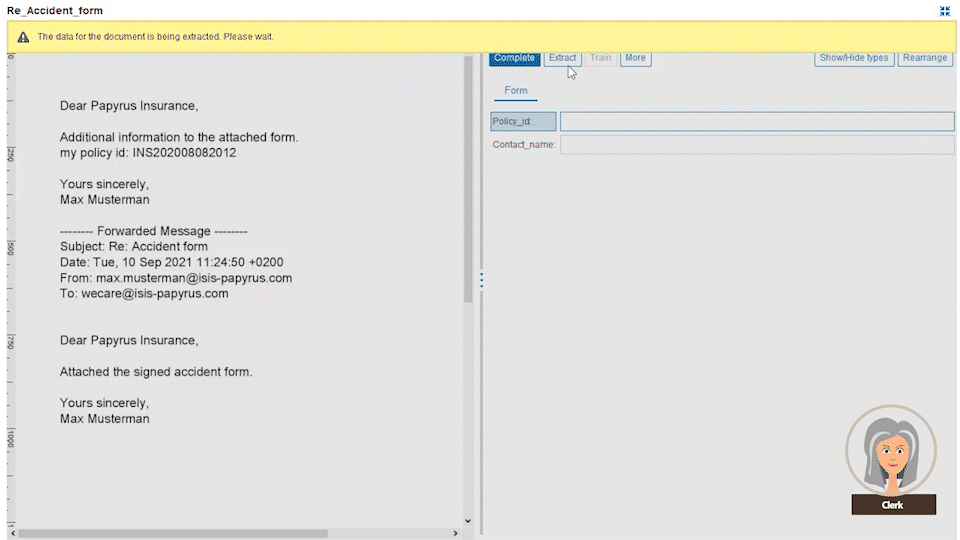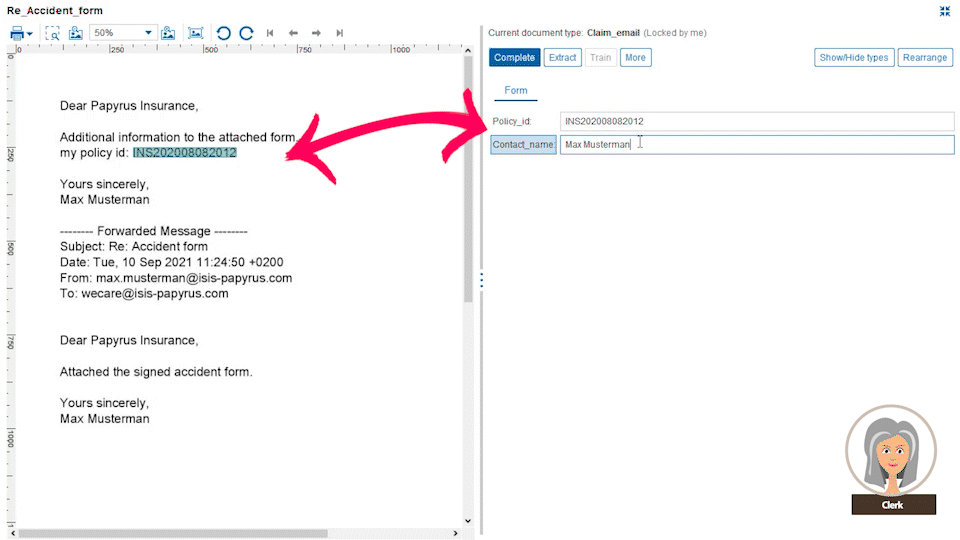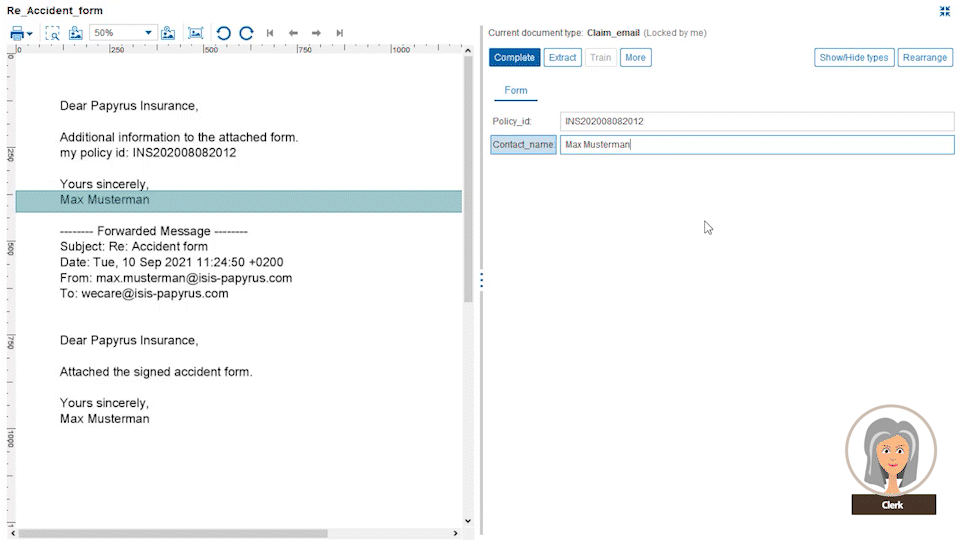
Business administrators define document data extraction templates from different custom document categories, like CVs, general emails, invoices or other document types which you exchange with your customers. These templates are defined with drag-and-drop data fields from the original document into the extraction form. For each field, a property like string, date, number, ZIP code, etc. is defined along with the placement it is typically found on the document page.
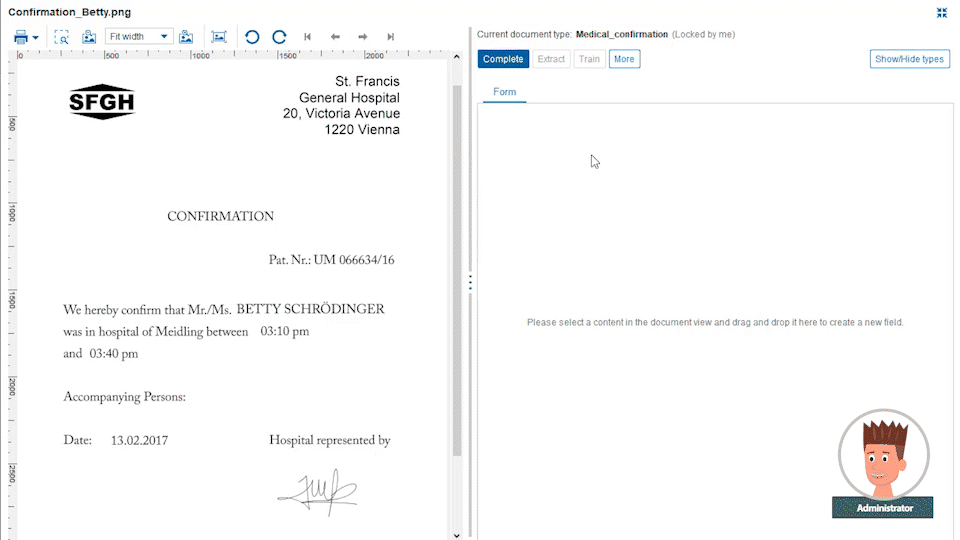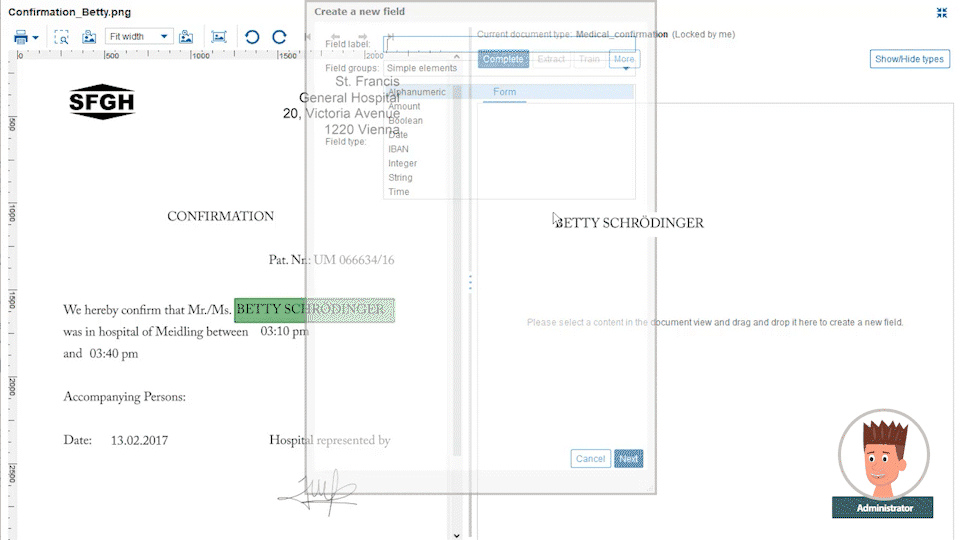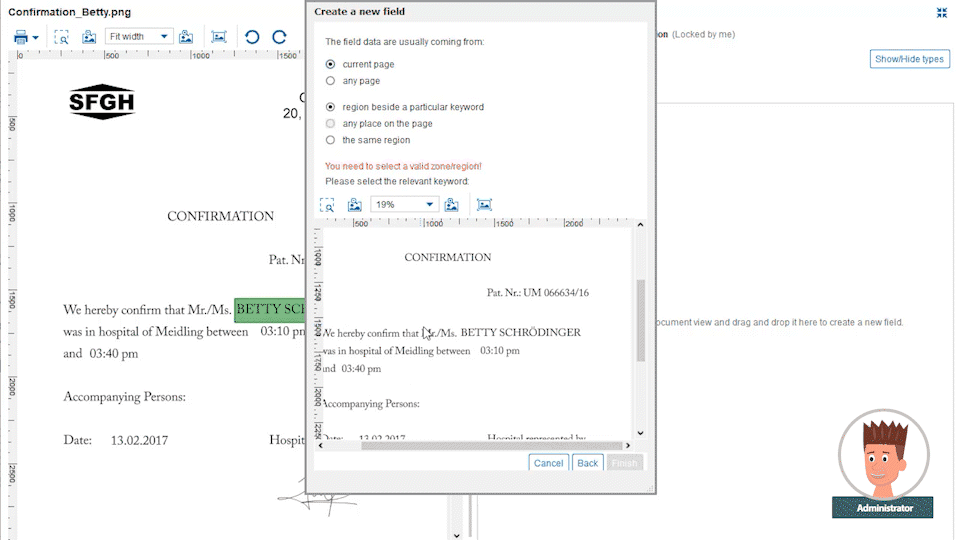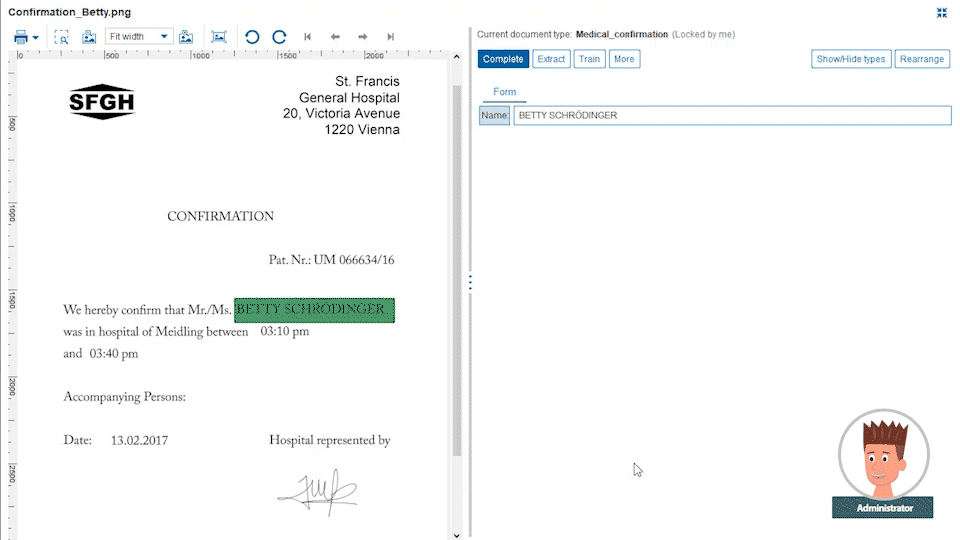
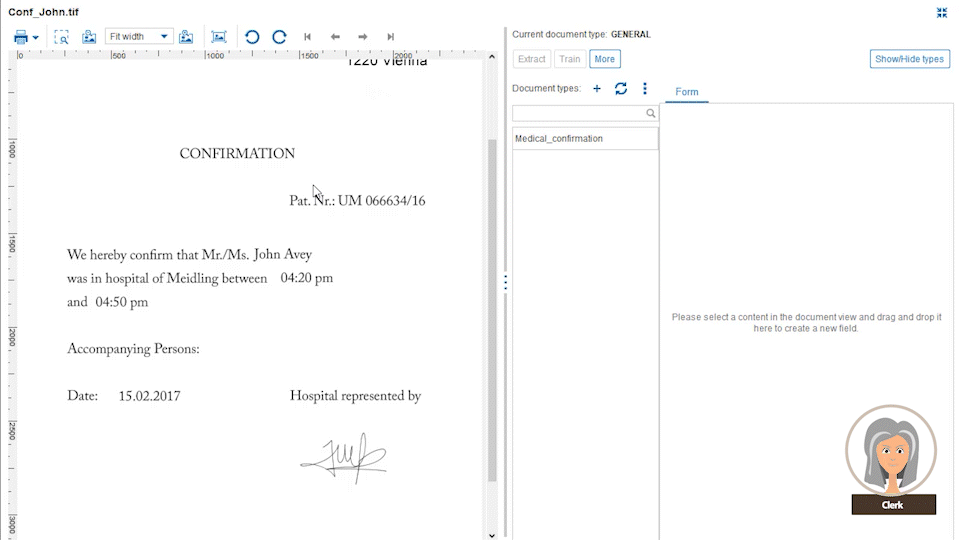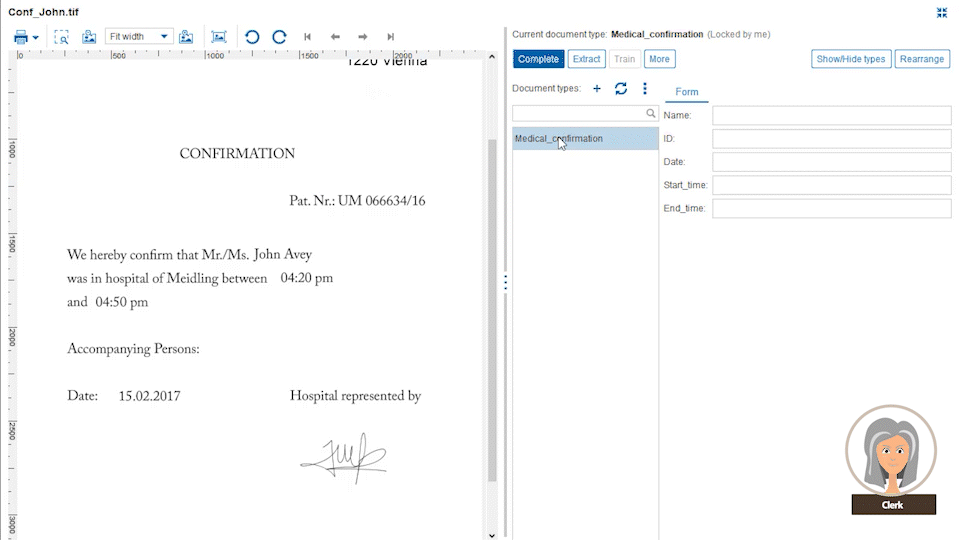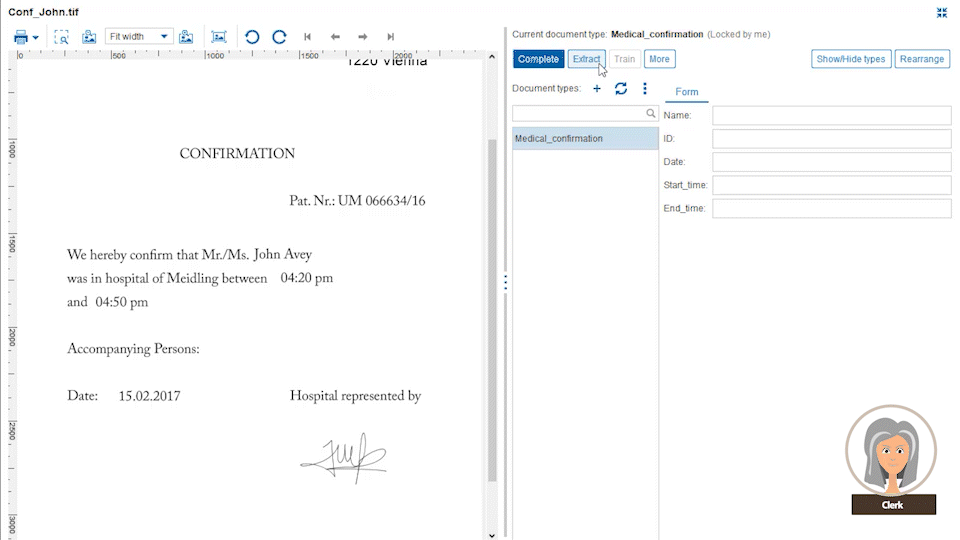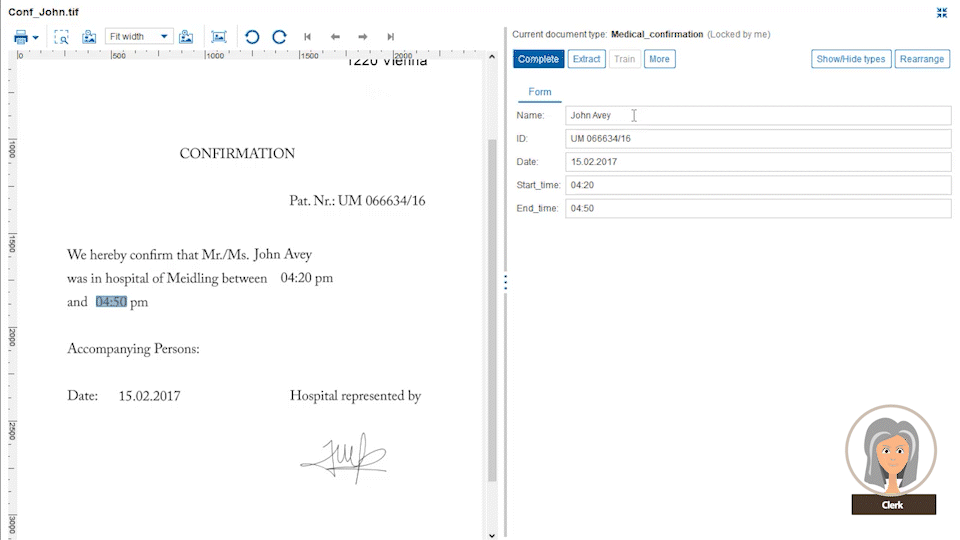
The power comes from the Papyrus field detection algorithm which will find the data not only at the currently spotted place, but also on other pages. The admin needs to specify only certain keywords that are related to it. Even complex tables can be easily extracted by defining the elements of a single row. The intelligent extraction algorithm applies the definitions to the full table.
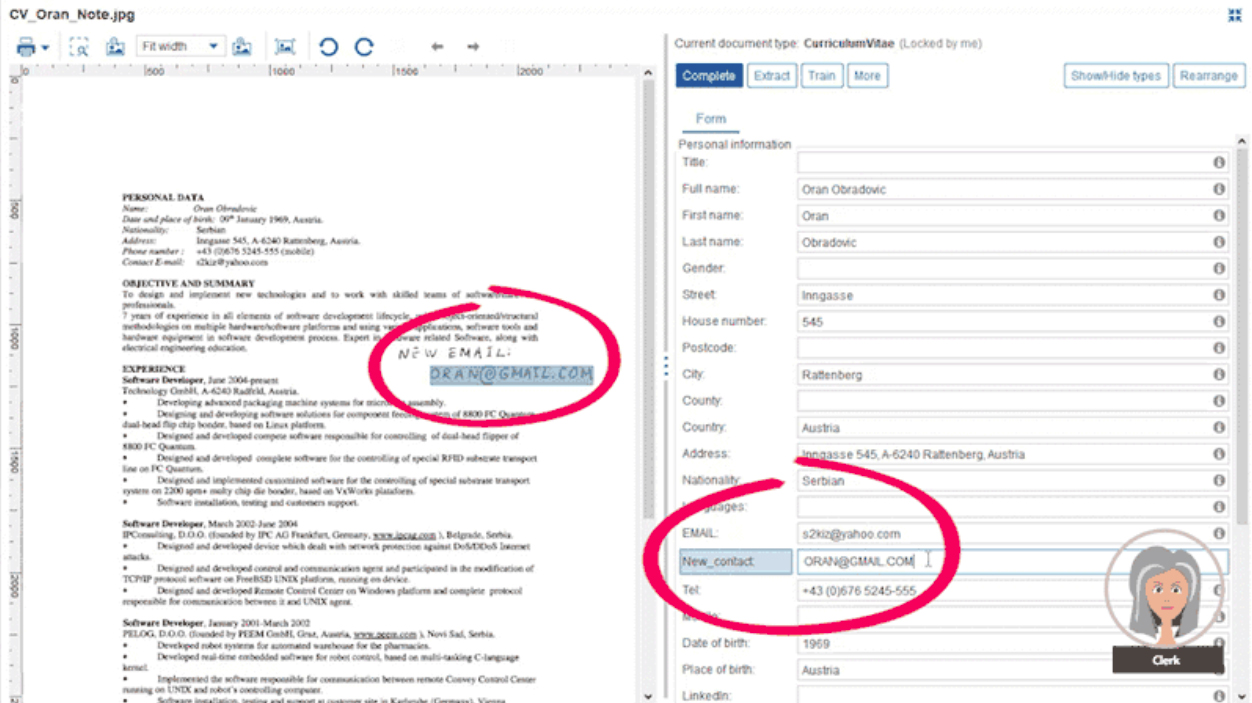
Users train the system further with different documents for each category. This way the system constantly learns from newly processed documents. Papyrus Capture also covers the extraction of handwritten annotations on documents.
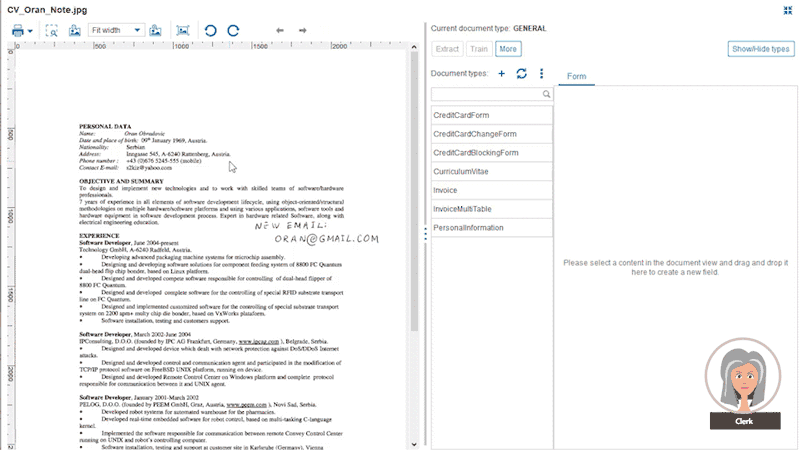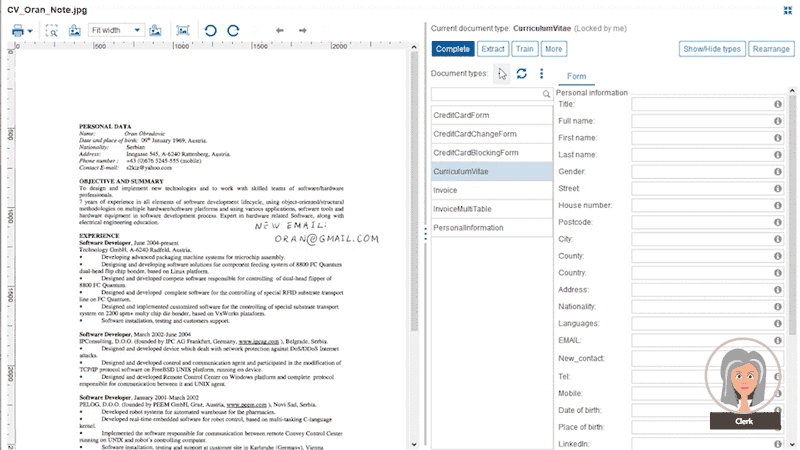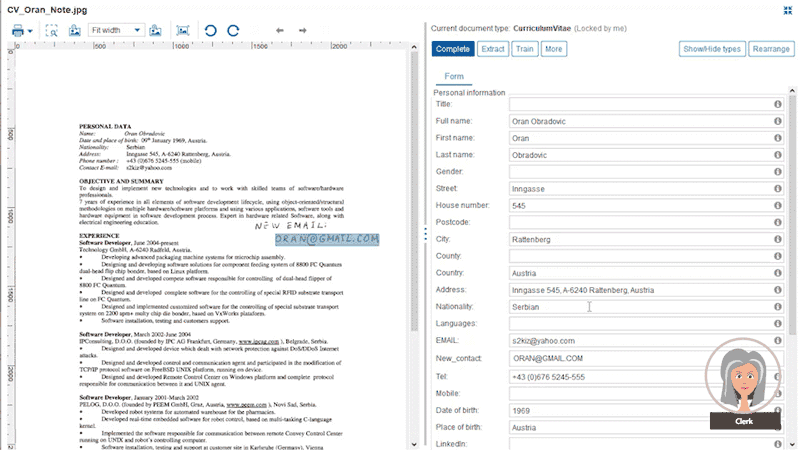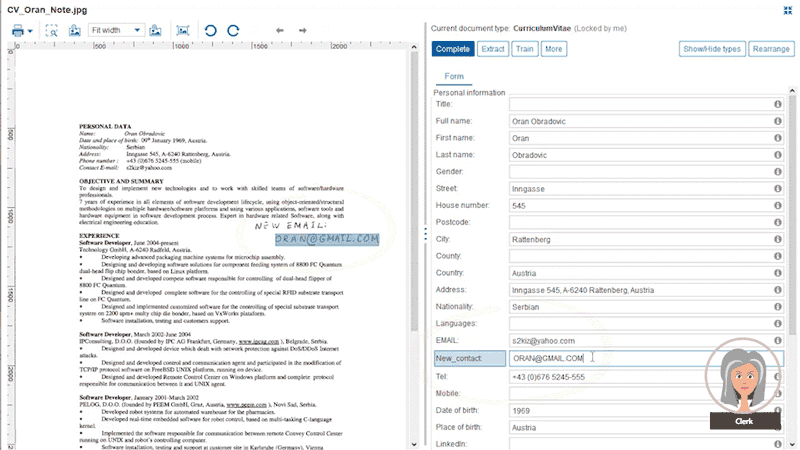
And if you have the need to automate completely unstructured email texts, we can assure you even that can be extracted by means of the Papyrus Business Designer.
Release Management included
Even hand-written annotations can be extracted from documents, which were originally not part of an extraction definition. Clerks can extend such definitions which will become available for all users, when the release and change management was successfully completed. For this purpose, the Business Designer has a dedicated release management workplace to define new releases, the release process itself and when it shall be released. Get started with one of the default release processes which come with the Papyrus Business Designer installation. But if you need your special process, just define it with the integrated Process Designer. It is really as simple as that to get new templates into production, after they were successfully tested.
Did we make you curious about training the machine with pattern recognition to achieve high automation of unstructured documents and emails? The Papyrus Business Designer supporting data capture and OCR extraction during content and case management operations will empower your business departments without requiring IT involvement.

Papyrus Academy Manager at Papyrus Software
Vienna, Austria




