
Product Description
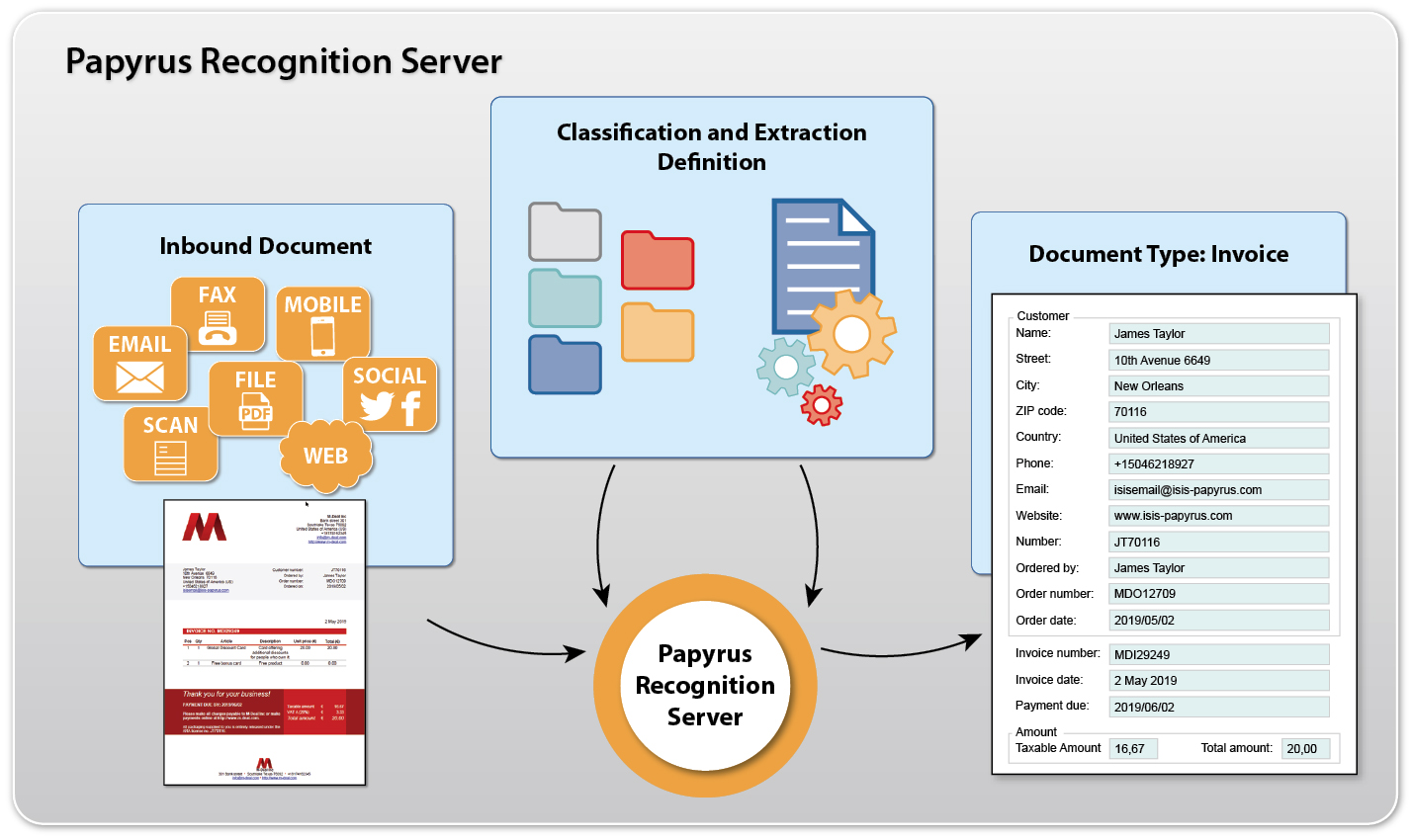
Papyrus Recognition Server is a powerful tool for automated high volume business content digitizing what is key for tight SLAs (service level agreements) in the modern business world.
The Recognition Server offers a broad range of possibilities for application in the field of automated sorting and distribution of electronic documents, fax and paper mail. For data extraction, the Recognition Server can identify unstructured and structured documents with great reliability. Various types of content: whether machine or hand written text, check boxes or diverse bar codes, QR codes, DataMatrixes - can be recognized and identified as business related content by means of powerful document analysis using pattern recognition, keywords, relative positions, voting algorithms, layout analysis and rules.
Papyrus Recognition Server applies classification and extraction definitions created with the Papyrus Designer Capture or Papyrus Business Designer /Capture to acquire the required business content from the inbound business mails.
Key Benefits
- Automated high volume content digitizing to keep business SLAs
- Powerful classification and extraction of business relevant content out of high volume of inbound data
- Excellent results for both FixForm and FreeForm® documents
- Support of documents from all common file formats and inbound channels such as scan, e-mail, mobile/photos, web and social media.
- Support of diverse recognition engines for different kinds of content, powerful preprocessing and extraction defined with Papyrus Designer Capture and Papyrus Business Designer.
Features
Document Classification
The purpose of the Papyrus Recognition Server for document classification is to enable an automated process of judging incoming documents according to selected criteria, sorting them into freely definable categories - thereby making information actually accessible for the company - and forwarding them accurately to those who are in charge of the issue.
Documents which could not be assigned to a class unequivocally are separated and presented to the administrator or clerk for further assessment.
Data Extraction
The Papyrus Recognition Server extracts and reads all necessary field data from the identified document class. This process can include unstructured layouts and structured forms with keywords at predefined positions.
Image Preprocessing
According to the applied classification and extraction definitions the following image pre-processing can be used:
- Dirt removal, Despeckle
- Punch hole removal
- Automatic rotation
- Binarize
- Convert color to gray
- Box, line, grid and combs remover
- Drop out color
- Dilate
- Erode
- Deskew on border
- Deskew on content
Recognition engines
Content of pre-processed images can be recognized by a powerful set of recognition engines belonging to the following main groups:
- Optical character recognition (OCR) – machine written text
- Intelligent Character Recognition (ICR) – hand written text
- Optical Mark Recognition (OMR) – check boxes
- Bar code, QR code, DataMatrix
- Logo
- Signature
Document structure analysis
To discover relevant content the following main possibilities and their mixture can be applied during the extraction process based on the prepared extraction definition:
- Patterns
- Keywords
- Regions
- Positions
- Anchor points
- Rules
- Layout
- Logo
Data Formats
The Papyrus Recognition Server can process the following data formats:
- TIFF 6.0 or higher (also multi-page)
- JPEG and JPEG 2000
- BMP
- GIF
- PNG
- HTML
- CSV
- TXT (plain text)
- PDF 1.4 or higher
- PDF/A (ISO 19005)
- AFP
- Office formats:
- DOC/DOCX/DOCM/ODT
- PPT/PPTX/PPTM/ODP
- XLS/XLSX/XLSM/ODS
Prerequisites
- Windows 7 or later; Windows Server 2012 or later
- Linux (SLES 11 or later, RHEL 5 or later)
- Papyrus WebRepository
- Papyrus Capture /Office-In for office formats support
- Papyrus PDF-in for native PDF support
- Papyrus Designer Capture or Papyrus Business Designer